Instacart Market Basket Analysis

INTRODUCTION
“You can’t wait for customers to come to you. You have to figure out where they are, go there and drag them back to your store.” — Paul Graham, Co-Founder Y Combinator
This quote above from Paul Graham, co-founder of Y Combinator, efficiently summarizes the high level objective of what we are trying to achieve. Through this solution, we want to help Instacart, an E-commerce company, that picks up and delivers grocery products to its customers, improve its customer experience by suggesting them which of their previously ordered products they are mostly likely to reorder.
This helps them save their precious time, that otherwise might get wasted by scrolling through the entire catalog for the products that they mostly reorder . Instead they can cross check the products that we suggest and add the remaining products to their carts manually.
Please go through the below blog, to know how we approach this problem of suggesting products to a user that the user might mostly reorder.
Table of Contents
- Business Problem Overview
- ML Formulation of the Problem
- Dataset for the Problem
- Performance Metric
- Existing solutions
- Exploratory Data Analysis
- Feature Engineering
- Preparing Train, CV and Test data
- Data Cleaning and Feature Scaling
- Addressing Imbalance Dataset Problem
- Creating custom metric function
- Baseline Modelling
- Advanced Modelling
- Model Comparison
- Kaggle Submission
- Future Work
- End Notes
- References
1.Business Problem Overview
Instacart like any modern day e-commerce or grocery delivery application wants us to make use of the data available from millions of previous orders and make predictions on what product that a user has already bought in his/her previous orders he/she might reorder.
This helps Instacart by reducing the amount of time taken by its user to browse through its catalog for products that the user generally reorders and instead the user can spend their time in Instacart for checking other products that are available to try on Instacart.
2. ML Formulation of the Problem
This problem is different from the classical recommendation problem (like Netflix recommendation system) as in classical recommendation problem, we generally recommend users, products (or movies) that are similar to the products that the users have already purchased( or viewed).
But in this problem, we have to recommend users the products, the user has already purchased. We are going to pose this problem as supervised learning binary classification problem. With binary labels being whether the previously ordered product will be reordered or not, we have to come up with features which summarizes the information about the user’s previous orders and the products contained in them.
3. Data Set for the Problem
The source of the data set is the data provided by Instacart itself for the Kaggle challenge Instacart Market Basket Analysis. The data can be acquired from https://www.kaggle.com/c/instacart-market-basket-analysis/data
We are given data of 200K unique users, with 4–100 orders for each of them. The number of distinct products are about 50K. The aisles, departments the products belong to and day of the week and hour of the day and similar time related details and other details are provided for each of the orders.
We are given three sets of data prior, train and test. Prior set contains all the users and their previously ordered products except for few last orders of the user. These few last orders of all the users are split between train and test sets. In the train set, all the products that the corresponding user have ordered/reordered have been given, while for the test set only the user and timing of the order is provided.
We were given 6 relational data tables in csv format. Namely aisles.csv, departments.csv, orders.csv, order_products__prior.csv, order_products__train.csv and products.csv
Orders.csv
This contains information of the users and their orders in all the datasets i.e prior, train and test with eval_set column indicating which set they belong. More over this contains information such as whether the given order is what number of order for the user and the day of week the order is placed, the hour of the day the order is placed and days since the past order of the user. Orders eval_set columns distinguishes the orders into prior, train and test sets.
Prior set contains first n-1 orders for all 206209 users. Train set contains order information of last order of 131209 users and test set contains last order information of 75000 users.
Columns: order_id, user_id, eval_set, order_number, order_dow, order_hour_of_day, days_since_prior_order
Order_products__prior.csv:
This contains information about the orders and their corresponding products and the order in which the products are added to the cart of the corresponding order and whether the products are reordered or not for the given prior data set.
Columns: order_id, product_id, add_to_cart_order, reordered
Order_products__train.csv:
This is the equivalent of Order_products__prior.csv but for train data set Columns: order_id, product_id, add_to_cart_order, reordered
Products.csv:
This contains product id, corresponding product name and the aisle id and department id to which the product belongs.
Columns: product_id, product_name, aisle_id, department_id
Aisles.csv:
This contains aisles and the corresponding aisle ids.
Columns: aisle_id, aisle
Departments.csv:
This contains departments and the corresponding department ids
Columns: department_id, department
4. Performance Metric
We are going to use binary f1 score metric for our problem. Before discussing f1- score in detail, let’s make sure we are perfect with the pre-requisites for f1-score, the confusion matrix, precision and recall.
Confusion matrix:

The above table depicts the confusion matrix for our binary classification problem. Confusion matrix is created as a grid of the two classes. One axis represent actual labels and the other represents predicted labels. The entire set of points is divided into four sections, namely, TP,TN, FP,FN.
TP represents True Positives, meaning, the number of actual positives that has been correctly classified as positives.
TN represents True Negatives, meaning, the number of actual negatives that has been correctly classified as negatives.
FP represents False Positives, meaning, the number of actual negatives that has been incorrectly classified as positives.
FN represents False Negatives, meaning, the number of actual positives that has been incorrectly classified as negatives.
We can see from the above picture, that TP and TN account to the total correctly classified points and FP and FN account to the total incorrectly classified points.
We are using notation P to indicate all actual positives, N to indicate all actual negatives, p to indicate predicted positives, n to indicate predicted negatives.
Ideally, we want TP and TN to be large and FP and FN to be too low. But since we can’t achieve this most of the times. We choose a trade-off based on the problem we are solving. We will explain shortly, how we are going to use this four metrics to come up with the appropriate metric for our problem.
Precision:
Precision is defined as the ratio of number of true positives to the number of predicted positives. The max value of precision is 1, happens when we are 100% correct when we predict a point to be positive.
Precision=TP/p=TP/(TP+FP)
This metric gives us the information on how correct we are, when we predict a point to be positive. We need to give importance to this metric as we do not want to clutter the user with all of his previous purchased products. If we do clutter the user, then he might get overwhelmed and entirely skip the help we are providing. Hence it is necessary to make precision high for our problem.
Recall:
Recall is defined as the ratio of number of true positives to the number of actual positives. The maximum value of recall is 1, happens when we are able to retrieve all the products the user might reorder.
Recall= TP/P = TP/(TP+FN)
This metric gives us the information on how many of the actual positives that we are able to retrieve correctly. We need to give importance to this metric as we do not want to miss out on any of the product that the user might most probably reorder. If we do not come up with a decent score for this metric, then we loose the purpose of solving this problem. The user will not find most of the products, he/she is looking for and has to go through all the catalog to find the remaining products he/she wants.
F1-Score:
F1- score is defined as the harmonic mean of precision and recall. It tries to balance both precision and recall. The maximum value of f1-score is 1, occurs when both precision and recall are 1.
F1-score= (2* precision*recall)/(precision+ recall)
Using F1-score ensures that we do not increase either precision or recall at the expense of the other. For instance, let us say if we choose only precision as our metric we can get precision score of 1 even if we do not predict any of the products as reordered. But in this case our recall will be 0, since we didn’t retrieve any of the products that are getting reordered.
On the other side, if we predict each of the previously ordered item of the user as reordered, we get recall to be 1 but our precision will be at stake. Hence it is important for us to balance both precision and recall so we will be able to retrieve most of the products that will be reordered making sure that most of the predicted reordered products are truly reordered.
5. Existing Solutions
2nd place Solution of Kaggle Challenge by Kazuki Onodera:
The second place solution of the Kaggle Instacart market basket analysis came from Kazuki Onodera, working at Yahoo!. In his blog (link in the reference section), he explained the importance of feature importance and how he came up with different levels of features. He has extracted several user related features, product related features, user and product related features and other time based features.
He used Xgboost for modelling and he combined several Xgboost models trained with different random seed and took average of the predicted probabilities. He came up with custom threshold for each order to convert probabilities into class labels.
He used a technique called f1-maximization where in he generated randomly all possible actual labels based on the probability of each product. He then used the threshold that maximizes the average f1 score for all of the possible actual labels. For more details on this method, please refer to his blog mentioned in the reference.
4th place solution of Kaggle Challenge by George Gui
The 4th place solution of Kaggle Instacart market basket analysis challenge came from George Gui. The key take away from his blog is that instead of taking the raw probabilities and coming up with a threshold, he multiplied them by a factor that is inversely proportional to the number of reordered products that has already been added to the order.
He used Catboost for modelling which gave him better results than XGBoost and used LDA technique to reduce the number of features. For more details regarding his approach, please refer to the link mentioned in the reference section.
We can observe that in both of the above references, they have come up with some technique to increase the f1 score. We in our approach as well, will introduce a logical and interpretable way of increasing f1 score. Please stick till the end of the blog to get to the same.
6. Exploratory Data Analysis
Let us perform some basic exploratory data analysis, to see what features can help us come up with an approach to solve this problem. First we perform univariate analysis followed by bivariate analysis.
Univariate Analysis:
Exploring User Behaviors:
In the below snippet of code we are calculating user_reord_prop, the proportion of reorders out of all the purchases of the user.

We can see from the above graph, that user with user_id 99753 has reordered more than any user followed by 82414 and so on. We are only displaying top 5 users with most reordered proportion as we have around 200K users.
Exploring Product Behaviors:
In the below snippet of code, we are calculating product_reord_prop, the proportion of reorders for a product out of its purchases across all its users.

We can observe from the above boxplot that “Raw Veggie Wrappers” are more often reordered than any other product followed by “Serenity Ultimate Extrema Overnight Pads” and so on. We are only displaying top 5 products with most reordered proportion as they are about 50k unique products across the data set.
Exploring days_since_prior_order:
In the below snippet of code, we plot both pdf and boxplot of days_since_prior_order and see how it is different for both of the classes.

We can observe from the above plot that the number of reordered products are higher when days since prior order is short and the peak difference occurring at 7 days, as the number of days since prior increases, the number of reorders seems to fall much short. We can also observe that number of reorders are higher at 7 days and 30 days there by showing us the trend that users try to buy certain products weekly and monthly.

From the above plot we can observe that days since prior order is less for reordered products than for non reorders. Hence a good threshold for days_since_prior_order can partly solve our classification problem
Exploring Order_dow:
In the below snippet of code, we plot bar plot of order_dow_reordered_prop, the number of reorders out of total purchases on a particular day of the week.

From the above plot, we can observe that the probability of reordering is more on 1st day of the week followed by 5th day of the week and so on.
Exploring Order_hour_of_day:
In the below snippet of code, we plot bar plot of order_hod_reordered_prop, the number of reorders out of total purchases that have happened on a particular hour of every day.

From the above plot, we can observe that the probability of reordering is more on 7th hour of the day followed by 6th hour of the day and so on. We can conclude that user reordering patterns lie in early morning hours 6–8.
Exploring Order_number:
In the below snippet of code, we try to observe how order_number can differentiate between the two classes

From the above plot, we can observe that when the order number is less than 10 the non-reordered class dominates and when order number is greater than 10, the reordered class starts to dominate.

This plot backs the previous observation, a threshold around 10 of order number can do a decent job in differentiating the classes
Exploring Aisle_id:
In the below snippet of code, we plot bar plot of aisle_reordered_prop, the number of reorders out of total purchases for a particular aisle.

From the above plot, we can observe that milk is the most reordered aisle followed by seltzer sparkling water followed by fresh fruits, eggs and so on
Exploring Department_id:
In the below snippet of code, we plot bar plot of dep_reordered_prop, the number of reorders out of total purchases for a particular department.
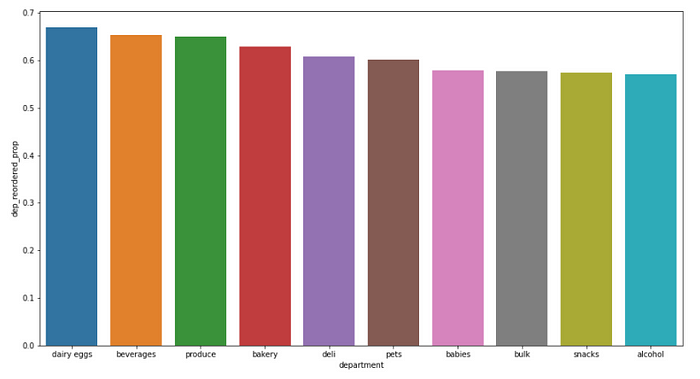
From the above plot, we can observe that dairy eggs is the most reordered product followed by beverages, produce, bakery and so on.
Exploring add_to_cart_order:
In the below snippet of code, we see how add_to_cart_order can differentiate between the two classes.

From the above plot we can observe that when add_to_cart_order is less than or equal to 5 , the number of reorders dominate while after 5, the number of non-reorders dominate.

This plot confirms the observation, during 0–5 we can see that reordered class dominates and post 10, non-reorders completely dominates.
Multi-Variate Analysis:
Exploring Order_dow and Order_hour_of_day can together:
In the below snippet of code, we plot heatmap of order_dow_hod_reord_prop, the proportion of reorders out of total purchases on a particular day of the week and hour of the day.

From the above plot, we can observe that probability of reordering is more on 1st day of the week 7th hour of day, followed by 1st day of week 8th hour of day and so on.
Exploring User and Product Together:
In the below snippet of code, we display user_product_cnt, the count of number of times a user has ordered a product.

From the above table, we can understand that a user reorders some of their products more often than the other products. In the above table we can observe that user 206209 has reordered ‘Diet Pepsi pack’ followed by ‘Calcium Enriched 100% Lactose Free Fat Free Milk’, ‘French loaf’ more than he/she reorders any other product.
EDA Conclusion:
We performed EDA on several different reordered count with different features. We found that some of the features contribute to the classification problem. Some of them were found to be not contributing alone to the classification problem, they might contribute in combination with other features. Following this we will extract more number of features based on reordered counts
7. Feature Engineering
Since in the EDA section we have found that several reordered proportions seems to be helping our problem. We will extract similar features. We will try to extract several user related, product related features similar to how we extract features for a recommendation system problem.
In total we have come up with around 50 features. Since average human attention span is too less to go through the approach of creating those 50 features, we are showing extraction of some decent number of features which sort of give the idea on how we are creating the remaining features. We have already covered some of these feature creation while we are performing EDA. You can always find in my GitHub on how to come up with other features. Link for the same is provided in the final notes section.
In the code snippet below, we are creating user_order_products_all_details, the dataframe containing all user-order and order-product information for the prior dataset.
User Features:
Extracting user_max_ono:
In the below code snippet, we will extract user_max_ono, the max order number for each user

Extracting user_uniqpr_prop:
In the below code snippet, we extract user_uniqpr_prop, the proportion of unique products present out of all the user’s purchases for each user.

Extracting user_order_reord_prop:
In the below code snippet, we extract user_order_reord_prop, the proportion of orders of a user that contain at least one reordered item.

Extracting different order size statistics:
Inspired from the 2nd place solution, we extract different order size statistics such as min order size, max order size, mean order size for each user.

Product Features:
Extracting product_ratios_users_oneshot:
Inspired from 2nd place solution, we will extract product_ratios_ users_oneshot, the number of users that buy the product only once.

Extracting product_cart_mean:
The below code snippet extracts product_cart_mean, the mean of add_to_cart_order for each product.

Extracting prod_uniq_us_prop:
The below snippet of code extracts prod_uniq_us_prop, the proportion of unique users out of total purchases of the product.

User and Product Features:
Extracting user_product_dow_mean:
The below snippet of code extracts user_product_dow_mean, the average of day of the week for each user and product combination.

Extracting user_product_hod_mean:
The below snippet of code extracts user_product_hod_mean, the average hour of the day for each user and product combination.

Extracting user_days_since_product:
Inspired from the 2nd place solution, in the below code snippet we extract user_days_since_product, the number of days that has passed since a user has ordered a certain product.

Add to Cart Order Features:
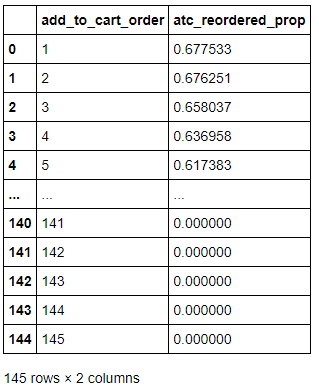
Extracting atc_reordered_prop:
The below snippet of code extracts atc_reordered_prop, the proportion of reorders out of total purchases for an add_to_cart_order.
Order_number and Days_since_prior_order Combination:
Extracting ono_dsp_reord_prop:
The below snippet of code extracts ono_dsp_reord_prop, the proportion of reorders out of total purchases with a particular order_number and days_since_prior_order combination.

Feature Engineering Conclusion:
We came up with several user features, product features, user and product combined features and so on. We came up with different reordered counts for several different column combinations. In the next section, we will see how we are preparing our train, cv and test data.
8. Preparing Train, CV and Test data:
Even though we were given reordered column value for every product in each order in train set, we can’t use the same as our class label. Our task is to identify which of the previously ordered products are reordered.
In order to create dataset for this task, for each user in the train and test, we gather all the products that the user has previously ordered. For this task, we use the prior dataset.
Now, we have all previously ordered products for each user. Now we assign labels for this user and product combination by checking whether this product exists in the product set of the last order of the user. Later we combine the features that we extracted using prior data with the data created above.
If we use train set for the above task we will be left with train data, if we do the same with test set we will be left with test set. Since we do not use the test set for modelling, we do not prepare the test set until we come to the final predictions section. We will use train data to both train the model and choosing best hyper-parameters by splitting this train data into train and cv data.
This process of splitting train set into train data and cv data is done by splitting the data using user_ids. We randomly shuffle the users of the train set and take 120K users’ data for our train set and the remaining 11209 users’ data as our cv data.
If you observe we follow the strategy of calculating fresh reordered labels by taking previous products and the strategy of splitting train data and cv data based on user_ids mimics how we were given test data. Mimicking test data to create train and cv data helps us to better evaluate and choose the best models.
In the below snippet of code, we show you how this is done. Although we show in detail, how to calculate the reordered labels, for feature merging we show only some feature merge to sort of give the idea on how it is done. You can always get the complete code in my GitHub link mentioned in the end notes section.
In the above snippet, we showed how to calculate reordered labels. In the next snippet we show how to merge features.
The above snippet gives you a glimpse of how to merge features extracted in the feature engineering section, later grouped into user_features, product_features, aislse_features, with the train data. In the next snippet, we will see how we have done the train-cv split.
In the above snippet, we saw how we we can do the train-cv split. One can follow the similar approach for creating train data to test data as well. In the next section, we will see how to scale our data.
9. Data Cleaning and Feature Scaling
We have null values present only in ono_dsp_reord_prop features, when we merge this feature with train data on a particular order_number, days since prior order combination that is not present in the train data. We cleaned our data by filling null values with 0. Since the ono_dsp_reord_prop feature gives us the proportion of reorders out of total purchases for a particular order_number and days_since_prior_order combination. It is quite interpretable and appropriate to fill these None values with 0. As the reordered proportion is 0 of the combination is not present in the prior set.
We do min-max feature scaling. Since we have limited memory resources and since sklearn min-max scaling takes much more memory than we can afford. We write custom snippet of code to do our min-max scaling. We find the min and max of each column of our train data and use this to scale train, cv and test data. Please find the code in the below snippet.
Since we have nice cleaned and scaled data, we will see how we are addressing the imbalance dataset problem.
10. Addressing Imbalance Dataset Problem:
We have a slightly imbalanced dataset with 6997130 non-reordered labels and 758820 ordered labels. Normally imbalance dataset is overcome by under-sampling dominant class or over-sampling the scarce class. By under-sampling the dominant class you might loose information brought by the excluded data. In case of over-sampling you need to create synthesized samples which may degrade the over-all quality of data we have. So to overcome these problems we either experiment with class-weight hyper-parameter where ever it is available or we will experiment with different thresholds of converting probabilities to labels. In the next section, we will look into the creation of our custom metric function mean_f1_score which mimics the metric used in the competition.
11. Creating Custom Metric Function:
Since the metric for the problem is mean f1 score, the average of f1 scores for every order. It is important to maximize this metric so that we do not perform extremely well on predicting reordered products of a particular user and perform poorly on remaining users. We defined the method to calculate this custom metric in the below snippet of code. In the next section we will do our baseline modelling with logistic regression.
12. Baseline Modelling with linear regression
In our baseline modelling, we do hyper-parameter search on the hyper-parameter C (the parameter that decides regularization) and the class-weight hyper-parameter of linear regression.
We have found best hyper-parameters to be C=10, Class-weight=50, we will fit logistic regression with the best hyper-parameters and calculate our metric the mean f1 score on both train and cv data for different probability thresholds.

We found that for threshold of 0.2 we found best train and cv mean f1 scores of 0.3450 and 0.3452 respectively. In the next section, we will build more complex models for solving our binary classification problem.
13. Advanced Modelling
Random Forest Classifier:
In the below snippet of code, we will do hyper-parameter tuning on Random Forest Classifier with n_estimators, class-weight and max-depth hyper-parameters. Due to memory limitations using custom loop of parameters.

From the above figure, we can observe that our best hyper-parameters are n-estimators =20, max-depth=15, class-weight={0:1,1:5}.
We will train Random Forest Classifier with best hyper-parameters obtained and measure the train and cv mean f1-scores.
Random forest classifier with best hyper-parameters gave train and cv mean f1 scores of 0.3985 and 0.3663 respectively.
XGB Classifier:
In the below snippet of code, we will perform hyper-parameter tuning on XGB Classifier with hyper parameters search on learning_rate, n_estimators, max_depth, min_child_weight, colsample_bytree, subsample parameters.
We found best hyper-parameters to be subsample=0.1, n_estimators=100, min_child_weight=7,max_depth=5,learning_rate=0.1, colsample_bytree=0.5. We train XGB classifier with these best hyper-parameters and evaluate the model with different thresholds.

From the above figure, we found out that best XGB Classifier with best probability threshold of 0.2 gave train and cv mean f1 scores of 0.3631 and 0.3626 respectively.
LGBM Classifier:
We perform hyper-parameter tuning of LGBM Classifier with hyper-parameter search on subsample, num_leaves, n_estimators, max_depth, learning_rate, colsample_bytree and class-weight.
We found the best hyper-parameters for lgbm classifier to be subsample=0.3, num_leaves=31,n_estimators=150,max_depth=8,learning_rate=0.04,colsample_bytree=0.3,class_weight={0:1,1:5}.
We fit lgbm classifier with best hyper-parameters and evaluate our train and cv mean f1 scores.
We found that LGBM Classifier with best hyper-parameters gave mean f1 score of 0.3660 and 0.3651 respectively on train and cv data.
Adaboost:
We experimented with Adaboost as well. It gave train and cv mean f1 scores of 0.341 and 0.341 respectively. Since this score is only comparable with base line model. Not sharing the code for the same here. But you can find it in my GitHub mentioned in the end notes section.
Neural Network with 7 Dense Layers:
We experimented with a neural network of 7 dense layers. For each epoch, we found the mean f1 scores of both train and cv by trying with different thresholds of converting probabilities to class labels. Go through the below snippet of code for model creation.

Go thorough the below snippet for model compilation and training.
In the below snippet of code, we will evaluate the best model and find our mean train and cv f1 scores.
Our neural network model with 7 dense layers gave train and cv mean_f1 scores of 0.3643 and 0.3640 respectively.
CNN Model:
Next we train our last model the 1-d CNN model with different filter sizes to captures different combination of features. The below snippet of code shows model creation.

In the next snippet of code, we will compile and fit our CNN model and save the model that gives best mean f1 scores for train and cv data.
In the below snippet of code, we will evaluate our best CNN model to find train and cv mean f1 scores.
With our best CNN model we got train and cv mean f1 scores of 0.367 and 0.365 respectively.
In the next section, we will compare all the models we have trained so far based on train and cv mean f1 scores.
14. Model Comparison
Let’s us compare our models trained above with train and cv mean f1 scores.

We tried five different models with hyper parameter tuning. Out of all the four models, Random Forest Classifier did well compared to the rest, with close margin with LGBM Classifier and CNN model.
15. Kaggle Submission
We made predictions on the test data that is prepared, cleaned and feature scaled similar to the train data (refer the section train, cv and test data preparation) with all the models that we have trained.
We through experimentation with the public score, were able to come up with a novel approach that is logical and quite interpretable. After making prediction of reordered products for each order, we added “None” category to the orders which contain only one or two products.
This is interpretable as for these orders we are confident of only one or two products being reordered. Hence there is a greater chance that even those one or two products to not be reordered for at least some of these orders. Since our competition considers “None” as a category itself. We add “None” to the list of products that are predicted to be reordered for these orders. This approach gave at least a boost of 0.005 for all of the models.
These are the Kaggle submission results for the different models post this novel approach.

We got best private and public mean f1 score of 0.38459 and 0.38677 respectively, for the predictions returned by the CNN model.

Given our private score we will be at 629th place in the competition out of 2461 total submissions. Our CNN model private score 0.38459 is close to the 629th place private score of 0.38456, with first place score at 0.40914. Our future work can help us greatly improve this ranking.
16. Future Work
In future apart from our novel approach of adding “None” for orders with only one or two predicted reordered products, we can also try f1 maximization technique proposed by Kazuki Onodera.
We can also try his approach of creating a separate model that is based on user level features that can predict “None” predictions. We can also try to come up with a lot of features that efficiently summarizes the prior data information and choose the best features post LDA.
17. End Notes
We tried to cover most of our feature engineering and modelling techniques in the blog. But due to the time constraint we are only tried to give a glimpse of our feature engineering and modelling techniques. You can always find the entire code in my GitHub repository https://github.com/sunil741/Instacart-masket-basket-analysis.
We have also deployed a web application to predict reordered products given order details in GCP. If time permits will create a blog on how to deploy ML models on GCP. But for now, you can view the code in my GitHub repository provided above.
These are the sample screenshots of how to use the above application.

For Now, not providing any link to the deployed application as I am not keeping the cloud instance active as there only a few free credits left and I currently can’t afford full-tier. Will update the link in the blog, if I can find any other option.
Let us get connected on linkedin.com/in/sunil-jammalamadaka-7459a9122 for much more ML interactions and content sharing. :-)
Until Next Time! Signing Off ! ….. A Fellow ML Enthusiast.
18. References
- https://medium.com/kaggle-blog/instacart-market-basket-analysis-feda 2700cded
- https://www.kaggle.com/c/instacart-market-basket-analysis/discussio n/38102
- https://www.kaggle.com/c/instacart-market-basket-analysis/discussio n/38100
- https://www.lexjansen.com/sesug/2019/SESUG2019_Paper-252_Fin al_PDF.pdf
- https://github.com/yudong-94/Kaggle-Instacart-Market-Basket-Analysis
- https://www.kaggle.com/gemartin/load-data-reduce-memory-usage
- https://www.analyticsvidhya.com/blog/2016/03/complete-guide-parameter-tuning-xgboost-with-codes-python/
- https://www.appliedaicourse.com/