Medical Chatbot Using Bert and GPT2

“Chatbots are important because you won’t feel stupid asking important questions. Sometimes talking to someone can be a bit intimidating. Talking to a chatbot makes that a lot easier!” — Petter Bae Brandtzaeg, project leader, Social Health Bots project.
INTRODUCTION
This quote from Petter Bae Brandtzaeg, project leader of Social Health Bots project highlights one of the key reasons why building medical chatbots is very important! It gives you no restraint on asking as many medical questions as you like, whenever and wherever you like.
There are significant advances that are made in the medical domain to help improve the interaction between a patient and a doctor. Earlier a patient has medical help only when the patient visits the hospital physically or when the doctor itself comes to the patient. But with the digitalization of the world some of the platforms offer patient-doctor interaction online. This interaction can be in many forms such as live phone calls, video calls, live chats, etc.
Although live communication provides much more immersive interaction between the doctor and patient, in terms of scheduling it may be little easier if the patient can just ask the doctor for a medical query and the doctor can find his suitable time to help the patient. With widespread development of machine learning techniques, there is a place in this flow where machine learning can perfectly exploit to significantly reduce the workload or assist the doctor and can simultaneously help with the patient with faster query resolution.
Table of Contents
- Business Problem Overview
- ML Formulation of the Problem
- Dataset for the Problem
- Performance Metric
- Existing solutions
- Overall Architecture
a. Finetuning BioBert and Training Question Embedding Extractor
b. Fine-Tuning the GPT2 Model
c. Putting It All Together
7. Sample Input and Output
8. Future Work
9. End Notes
10. References
- Business Problem Overview
In this case study we aim to automate some of these query resolutions with automation. This way when the patient asks a question, the chatbot itself that has been trained on such question-answer pairs can try to come up with an answer. If at all the patient is not satisfied with the answer generated by the chatbot, the chatbot itself will suggest some of the previously answered similar question-answer pairs. If the patient doesn’t get his or her answer then we may redirect him to an actual doctor.
This way we can ensure that both the doctors ‘ and patients’ time is conserved. This is achieved by not overwhelming the doctor with a lot of patients’ questions since they are filtered at each stage of the chatbot, the number of patients that still want to contact the doctor will reduce significantly. At the same time not making patients wait for the doctor to reply to the query significantly reduces the patient’s waiting time and enables the patient to come up with a quick action in solving his/her problem.
2. ML Formulation of the Problem
There are two main components to solve the problem which might include many sub-components. Since at first, we are trying to generate an answer to the patient’s query we can pose this problem as a seq2seq task trained in supervised fashion from previously answered question-answer pairs.
Secondly, when the patient is not satisfied with the answer provided, we have to show the patient similar questions with answers that have been previously answered by a doctor, this we do by doing a semantic search task in an unsupervised fashion. Although we will train neural networks to generate question and answer embeddings which we use to do this semantic search. These embeddings are generated using supervised learning binary classification approach which we will discuss as we progress through the blog.
3. Dataset Analysis:
For this task, we use the medical question answer dataset prepared by Lasse Regin Nelson. This dataset is uploaded in his GitHub https://github.com/LasseRegin/medical-question-answer-data. He has gathered such question answer pairs from prominent medical websites such as eHealth Forum, iCliniq, Question Doctors, WebMD where real doctors have provided public answers to the questions asked by patients. We thank the above websites and Lasse Regin for helping us with the dataset and enabling us to help the medical community further.
The above picture shows a sample data provided in the GitHub. We were provided with about 25K question answer pairs. Along with the question answer pairs we were also given tags to efficiently categorize the questions into belonging to a particular disease, etc. The number of unique tags we are given in total are about …. We are also provided with the URLs from where we can find these question, answer pairs.
4. Performance Metrics
There are different components in this task which require different performance metrics. For the task of seq2seq generation, instead of relying on bleu score for measuring the efficiency of our model, we rather evaluate it by the manual interpretation of the quality of answers generated. The reason for not using bleu score is, even though it is generally used for evaluating seq2seq tasks, it is still not highly reliable for us to judge our model on this bleu score, at least for our biomedical task, as for some sentences it may give a very good bleu score and for some others it might give very low bleu scores. To better judge the model, the answers generated by the model should be open sourced to be judged by medical experts, only then we can come up with a correct evaluation of the model.
For the task of semantic search although we do not have a labelled dataset indicating which questions are similar to calculate the overall metric, we use cosine similarity to evaluate the embeddings of question and answer returned by the model.
5. Existing Solutions
https://arxiv.org/ftp/arxiv/papers/1901/1901.08746.pdf
This link refers to the BIOBERT: a pre-trained biomedical language representation model for biomedical text mining proposed by Jinhyuk Lee et.al. The authors of the paper demonstrated how a pre-trained bert architecture whose performance is state of the art in performing many different NLP tasks is still low on medical tasks due to the language model shift across domains.
The authors proposed BioBert to leverage this shortcoming of the pre-trained BERT model in the medical domain. They achieved this by training the previously trained BERT model on a large biomedical corpus such as PubMed Abstracts, PMC full-text articles.
This pre-trained model is then demonstrated to work for many different medical domain tasks by finetuning it to tasks like Named Entity Recognition (NER), Relation Extraction (RE) and Question Answering( QA). They showed that BIOBERT performed significantly better than BERT at most of these tasks for different datasets.
https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
This link refers to the “Language Models are Unsupervised Multi task Learners” paper proposed by Alec Radford et.al. In this paper the authors introduce GPT-2 model, an extension to the GPT model proposed by the same authors.
In this paper, the authors demonstrated that the GPT( Generative pre-training mode) model that is trained to learn the language model by training it to predict the next token given the previous tokens can achieve state of the art performances on specific tasks without training the models explicitly on the specific task.
The architecture of the model is the decoder part of the transformers with few changes and is trained on filtered web crawl data to maintain the quality of the data and the dataset includes data coming various domains to better generalize to the data for each domain.
These zero-shot learners does not need any fine tuning on the specific datasets and is able to beat 7 out of 8 language modelling datasets. This is achieved even with underfitting to the training data. Further training the model can give much more better results and can significantly improve the state of the art performances.
The model is also verified whether it is memorizing the training dataset to perform well on the test dataset by calculating the overlap between the task specific datasets and the training dataset of the model and it is found there in only about 2% overlap between the training dataset and any other test datasets, confirming that the model is generalizing rather than memorizing. The success of the model is largely credited to its large sized architecture consisting of about 1.5B parameters and massive web crawl dataset of 8 Million documents which amounts to about 40GB of text.
https://github.com/ash3n/DocProduct#start-of-content
The above link refers to the GitHub page of Doc Product: Medical Q&A with deep learning models. The model architecture was built using pre-trained BioBert and GPT models to generate an answer to a new question.
This is achieved in two stages. Firstly, given an input question, semantic search is performed with a representation of this question to obtain answers from the dataset which have some semantic meaning to the given question that have been encoded earlier.
This encoding of question and answers is done by using the same pre-trained BioBert model that encodes both the given question and the given answer of the training dataset separately, whose output is passed to two separate fully connected neural networks to get final question and answer representations. These FCNN are trained using the dataset whose positive samples are created by taking question and answer from the same pair and negative samples are created by taking question and answer from different pairs.
Once the first stage returns the answers that are semantically related to the given question, in the second stage, a fine tuned GPT2 model uses the concatenated sequences of both the new input question and these answers to generate an answer for the new question. This GPT-2 model is fine-tuned by teaching to predict the answer correctly to the question from the question-answer pair the answer belongs to, by passing the question and passing semantically similar answers present in the dataset apart from the answer itself.
It was found through experimentation that BioBert need not be fine-tuned for the task as it is already excelling at the task of representing biomedical terminology and since the FCNNs have their own parameters that can be learned to perform the task well.
6. Overall Architecture
Our overall architecture is inspired from our reference DocProduct, from which we use the idea of using pre-trained BioBert model to extract embeddings for previously answered question and answer pairs and use these embeddings to do a semantic search on the existing question-answer pairs.
These question-answer pairs concatenated with the original patient question are fed to the pre-trained gpt2 model as a context which is trained by comparing the original answer to its generated answer given this context.
In additions to these, we have introduced a key component that makes sure while fine-tuning the BioBert model we do not directly pass the randomly generate negative samples but instead we make sure that the tags for these randomly generated negative sample answer do not contain any of the tags that are present for the original question. This way we make sure that our quality of embeddings is maintained by not mistakenly treating similar question and answer as negative samples.
We have also successfully shown a way to fine-tune gpt2 model in tensorflow 2.0 for the seq2seq problem, there by reducing the efforts of our readers to find the same which we have personally faced. We are able to successfully integrate hugging face transformer models library to achieve this task. Overall, in comparison to our reference, not only we have added an additional filtering system but also produced a clean reusable code that exploits the open source hugging face library.
The overall architecture in the inference stage looks like this. We will discuss the training part of each of the components in details as we go.

First, when a patient asks a question, using the fine-tuned BioBert model and the trained Question Embedding extractor network, the question embedding are extracted. Further using these embeddings, FAISS searches answers and the corresponding questions that are “cosinely” similar to the given question in terms of embeddings and return these similar question-answer pairs in sorted order of their cosine similarity with the given question.
These ranked question and answer pairs Q1-A1, Q2-A2, Q3-A3 are then concatenated with the original Question Q as: Q3A3Q2A2Q1A1Q. The reason for such an order is to make sure that most similar question-answer pair Q1A1 is as close as possible to the original question asked. This concatenated string in then passed as context to the fine-tuned GPT2 model so that it generates the output sentence in the Q3A3Q2A2Q1A1QA’ where A’ is the generated answer.
Now having seen how the final inference pipeline works, let us see how each component in the above inference pipeline is trained. Let us start with BioBert model and the Question Embedding Extractor Model.
a. Finetuning BioBert and Training Question Embedding Extractor:
i) Dataset Preparation:
To understand how the BioBert model and the Question Embedding Extractor model is trained, let us first look at how the data for the same is prepared.
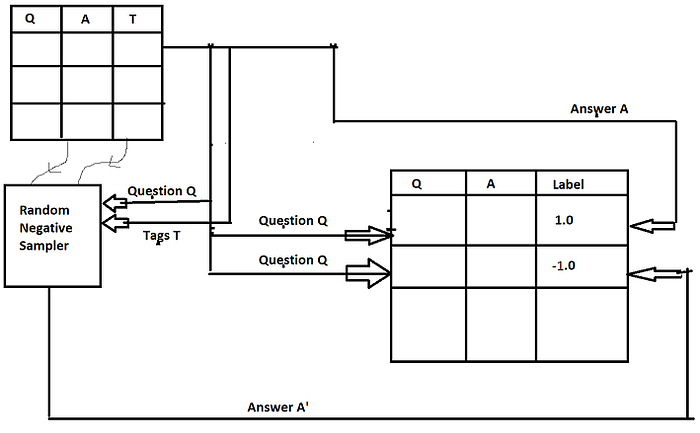
In our dataset, along with question and answers, we were also given tags which indicate the category to which the question and answer pair belongs. So for every Question Q and the Corresponding Answer A and tags T, we take the question-answer pair as the positive label(1.0) and for generating negative samples, we use both the original Question Q and the corresponding Tags T and generate negative sample Q’,A’, T’. We generate this negative sample by randomly picking up a tuple and checking whether the intersection between T and T’ is null. If the mentioned intersection is null then we take this Answer A’ and pair it with the original Question Q and consider this as the negative sample. If the intersection is not null, then we have to repeat the process of random sampling and checking for intersection. The below code implements the above.
ii) Data Pre-processing:
There are a few other minor details that we need to discuss about how we have preprocessed the question and answer text data. Preprocessing of the given question and answer data consisted of decontracting some of the words such as “won’t” to “will not”, remove unnecessary symbols such as !,etc. We also do not want to pad most of the question and answer with the padding constant. Therefore, when we calculated different percentiles of both question and answer data, we found that about 100% of all questions data and 99% of all answers data lie within 500 words. So post tokenizing, we truncated our sequences to a max sequence length of 512, this way we can use both the default pre-trained weights of BioBert and we do not lose any information. We also needed to pass attention mask to the BioBert model so that it understands that it has to focus on the actual content rather than on the padding token. The below code will implement the described.
Now, we have our data ready let us see how we have defined the question extractor model, answer extractor model and how we fine-tuned the pre-trained hugging-face BioBert transformer to achieve the task of classifying whether a given question and answer relate to the same context.
iii) Model Creation and Training:
From the above code, we can observe how we have created the MedicalQAModelwithBert which consists of a shared pre-trained BioBert Model and two residual blocks with dropout each for question and answers data. We used residual blocks so that we want to enable the model to directly pass the BioBert embeddings incase it finds to be best. The dropout makes sure that we can overcome overfitting as far as possible. After we get the embeddings for both question and answer after passing through the respective residual blocks, we than calculate the cosine similarity between them.
The model is then trained using mean squared error loss between the expected cosine similarities -1.0 and 1.0 and the cosine similarities returned by the model. We chose the best model that performed well on both train and validation data, after trying with various thresholds to classify between positive and negative classes.
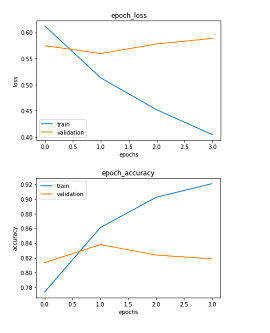
iv) Model Evaluation on Validation Data:
We compared the cosine similarities returned by the model for the validation dataset for both correctly classified negative and positive points, as well as the cosine similarities returned by the model for misclassified points that are originally negative and positive points. Please have a look at the below plots for the same.


From the above plots, we can observe that the correctly classified negative and positive points are well separated from each other while the incorrectly classified positive and negative points are very close to the threshold of 0.3 for which the model gave best train and validation accuracy. These two plots indicate that our model when differentiating correctly makes sure that we are well able to cosinely separate positive and negative points and when it fails to classify, it only does by a small amount.
v) Extracting Question and Answer Embeddings from the Model:
Now given that we trained the model, let us look at how we extract the question and answer embeddings from the mode. We pass the question and answers to the fine-tuned BioBert model and pass it to both the residual blocks of question and answer and then we store both these embeddings along with the question and answers to be used for semantic search.

b. Fine-Tuning the GPT2 Model:
i) Data Preparation:
Having trained the BioBert Model and extracting the question and answer embeddings, let us look at how we are going to prepare the data for training our GPT2 model.
Our first task is, for each patient question in the train dataset we do a semantic search to fetch similar answers and the corresponding questions. To do this task we use FAISS library from Facebook. We are doing cosine similarity FAISS search using the pre-computed embeddings of each answer in the dataset and the embeddings of the current question. FAISS along with giving similar results, gives a score on to how similar they are and gives them in sorted fashion.
Now once we get the ranked similar question-answer pairs to the given question and answer in the train dataset, we combine these ranked similar question-answer pairs Q1,A1,Q2,A2,.. with the original question Q and corresponding answer A to get the following string.
“..`Question: Q2 `Answer: A2 `Question: Q1 `Answer: A1 `Question: Q `Answer: A”
Now they are two things that we need to which we need to pay attention. First, notice how we explicitly mentioned the start of question and answer with special strings “`Question” and “`Answer”. These allow the language model to learn that once it encounters “`Question” it should expect a question and the same applies for answer as well.
The next thing we need to observe is that the most similar question-answer pair Q1-A1 is more closer to the original question-answer pair Q-A than Q2-A2. This allows our model to have a better recent context while learning the language model. Since our pre-trained GPT-2 Model was trained using max sequence length of 1024. We only take the last 1024 tokens, post tokenizing. In this process, we can observe that since question-answer pair with greater similarity lies close to the original question, whatever context is lost will be from the relatively less similar question-answer pairs. Hence our format helps solving this data loss issue as well. The below figure shows the data preparation pipeline for GPT-2.

Since we know that GPT-2 learns the language model by learning to predict the next word by taking the entire sentence before the word as context, we have to make sure that GPT-2 model is aware that when we give Q2A2Q1A1QA to the model it should learn to predict A taking Q2A2Q1A1Q as context. To do this we calculate the loss mask and while calculating the loss for GPT-2 predictions, we multiply this loss mask with the original loss so that it learns to predict the answer to the question asked taking both the question and the previous similar question-answer pairs data. Please go through the implementation of the same below:
ii) GPT-2 Training:
Now we have our dataset ready, let us see how we are going to train our GPT-2 model with the custom loss function.
In the above code, we can see how simple it is to train the hugging face GPT-2 model using TF gradient. Even though the batch size of dataset is 1, updating the gradients every 50 iterations made it easy for us to train with higher batch size in spite of having memory limitations.
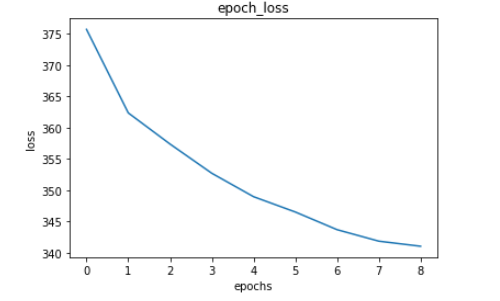
iii) GPT2-Model Evaluation:
We generated answers for 5 questions each from both train and validation dataset using the model that gave least train loss. Although the bleu score is high for some of the answers and low for some other, overall we were able to generate decent looking answers for most of the questions. Please have a looks at both the training and validation answers that have been generated. Note: The first line is the entire context, the second line is the actual answer and the third line is the generated answer in each paragraph.


7. Put It all Together
Having seen the final inference pipeline and how each individual component is trained, let us look through code how when given a patient question it passes to the question extractor model to get the question embeddings, how these embedding are used to fetch similar question-answer pairs, post obtaining these question-answer pairs how they can be used to generate the answer to the question.
8. Sample Input and Output:
Please have a look at the below screenshot to have a look at the sample input and the output that is generated by our framework.

Instead of just returning the generated answer, we have also displayed the ranked previously answered question-answer pairs that are similar to the given user question. Please have a look at the below image for the same. Please have a look at the deployment.py for the alternate version code.

9. Future Work:
In the future, we can experiment on how a transformer model can work on solving this problem directly as a seq2seq problem. Even if transformer model can directly generate answers to the given question, we still need BioBert to extract similar patient question-answer pairs. We can also work on gathering more biomedical data so that the model doesn’t overfit to the given data and can generate more appropriate answers.
10. End Notes:
For the complete code and details on how to prepare the data, training BioBert model, setup FAISS similarity search and training the GPT-2 model please refer to my GitHub repository at https://github.com/sunil741/Medical-Chatbot-using-Bert-and-GPT2. Please connect with me on LinkedIn at https://www.linkedin.com/in/sunil-jammalamadaka-7459a9122/ for collaborations and many more ML related projects. Until Next Time…. A Fellow ML Enthusiast.